|
I am a Research Scientist at Physical Intelligence working on building generally intelligent robots. Previously, I was a Senior Research Scientist at Google Deepmind working on the Gemini Robotics team. Broadly speaking, I am excited about bridging the general-purpose capabilities of vision and language foundation models with algorithmic paradigms for learning from interaction, such as imitation learning and reinforcement learning. I did my PhD in Computer Science in the AUTOLAB at UC Berkeley and completed my bachelor's degree at Caltech in Electrical Engineering. Below are selected publications which are representative of my current research interests -- please see my CV for a full account of my prior work. |

|
|
|
|
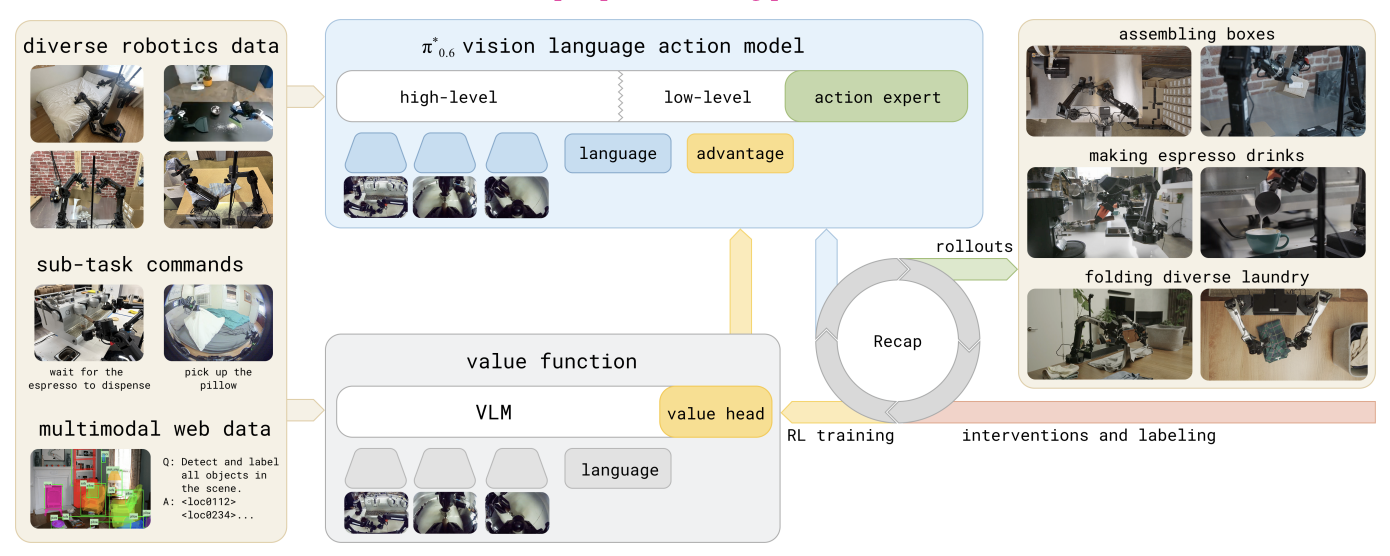
Physical Intelligence Team Preprint, 2025 Website / PDF A VLA that uses coaching and reinforcement learning to gain reliability from its own experience. |

|
Gemini Robotics Team Preprint, 2025 Website / PDF Using Gemini to create a thinking VLA which can do complex, multi-step reasoning across various robot embodiments. |
|
|
Gemini Robotics Team Preprint, 2025 Website / PDF Using Gemini to achieve highly generalizable and dexterous robot manipulation. My specific contributions were focused on post-training algorithms and evaluations. |
|
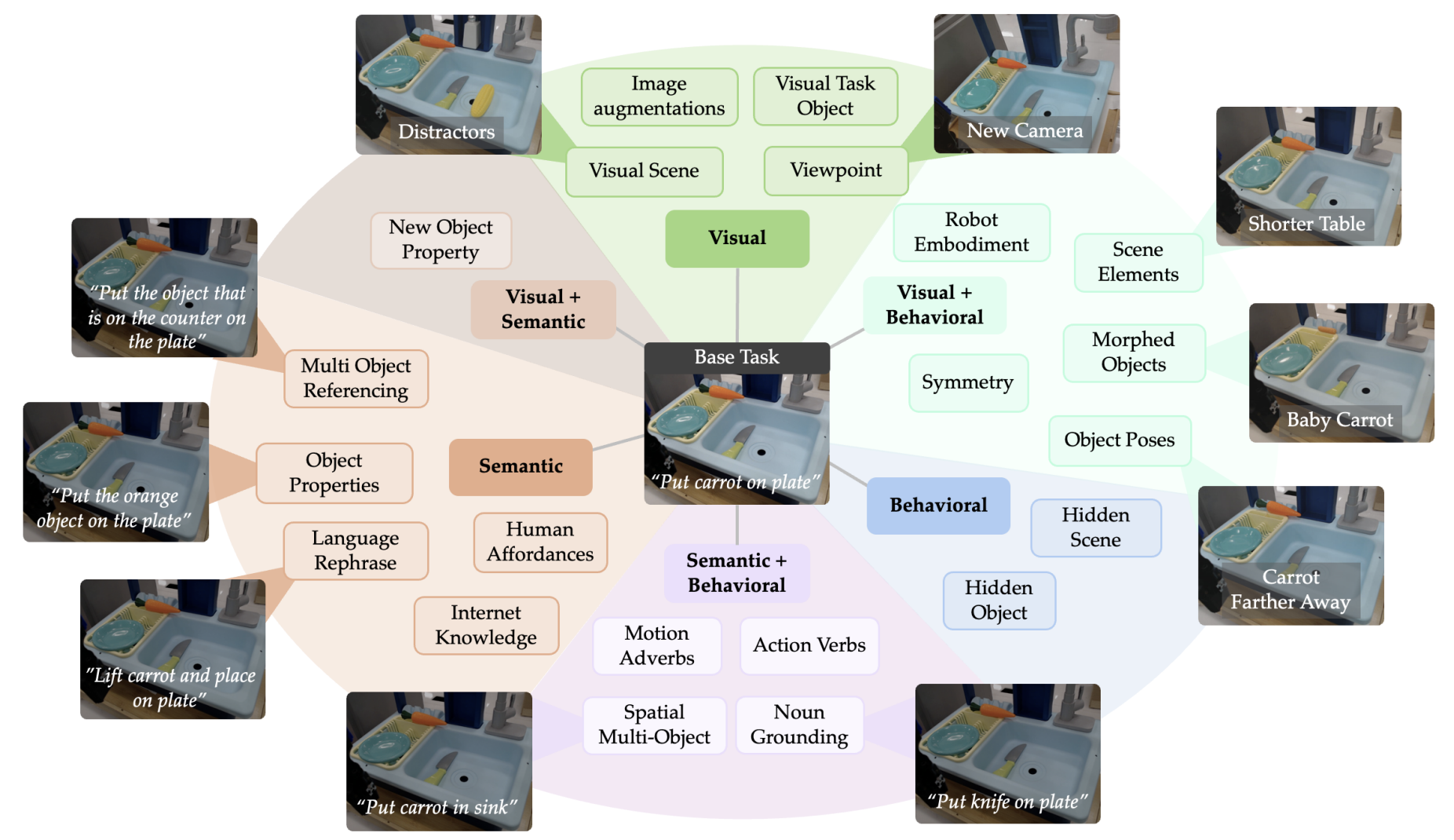
Jensen Gao*, Suneel Belkhale*, Sudeep Dasari, Ashwin Balakrishna, Dhruv Shah, Dorsa Sadigh Preprint, 2025 Website / PDF A framework and benchmark to evaluate the generalization capability of robotic manipulation policies across a number of axes, including visual, semantic, and behavioral generalization. |
|
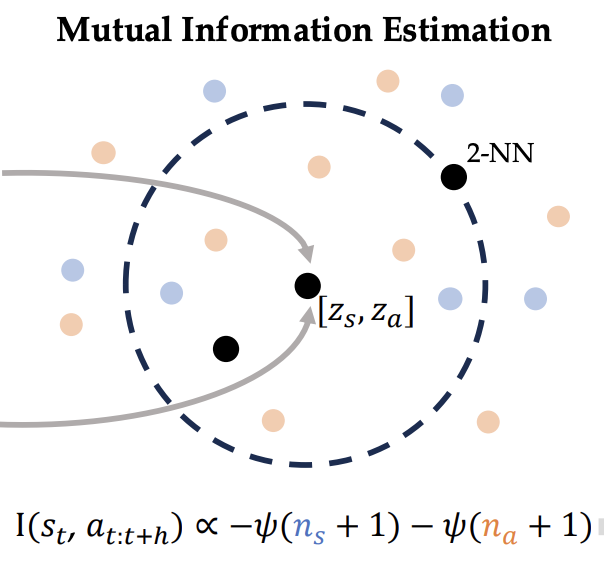
Joey Hejna, Suvir Mirchandani, Ashwin Balakrishna, Annie Xie, Ayzaan Wahid, Jonathan Tompson, Pannag Sanketi, Dhruv Shah, Coline Devin, Dorsa Sadigh Robotics Science and Systems (RSS), 2025 Website / PDF A simple and general method to filter robotic manipulation datasets for high quality demonstrations. |
|
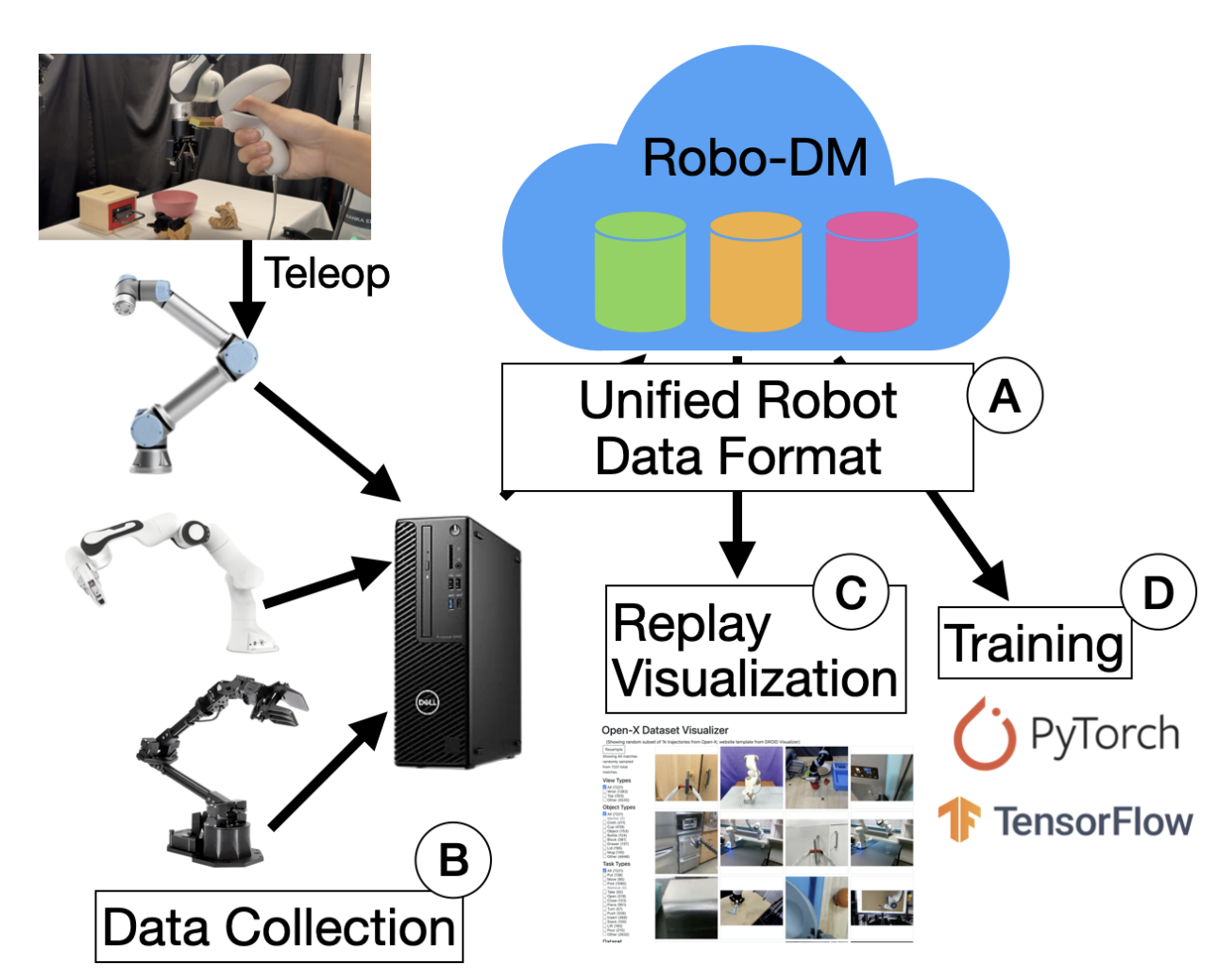
Kaiyuan Chen, Letian Fu, Siyuan Fu, Lawrence Yunliang Chen, Huang Huang, Kush Hari, Ashwin Balakrishna, Pannag R Sanketi, John Kubiatowicz, Ken Goldberg International Conference on Robotics and Automation (ICRA), 2025 - Best Robot Learning Paper Website / PDF A simple and general method to filter robotic manipulation datasets for high quality demonstrations. |
|
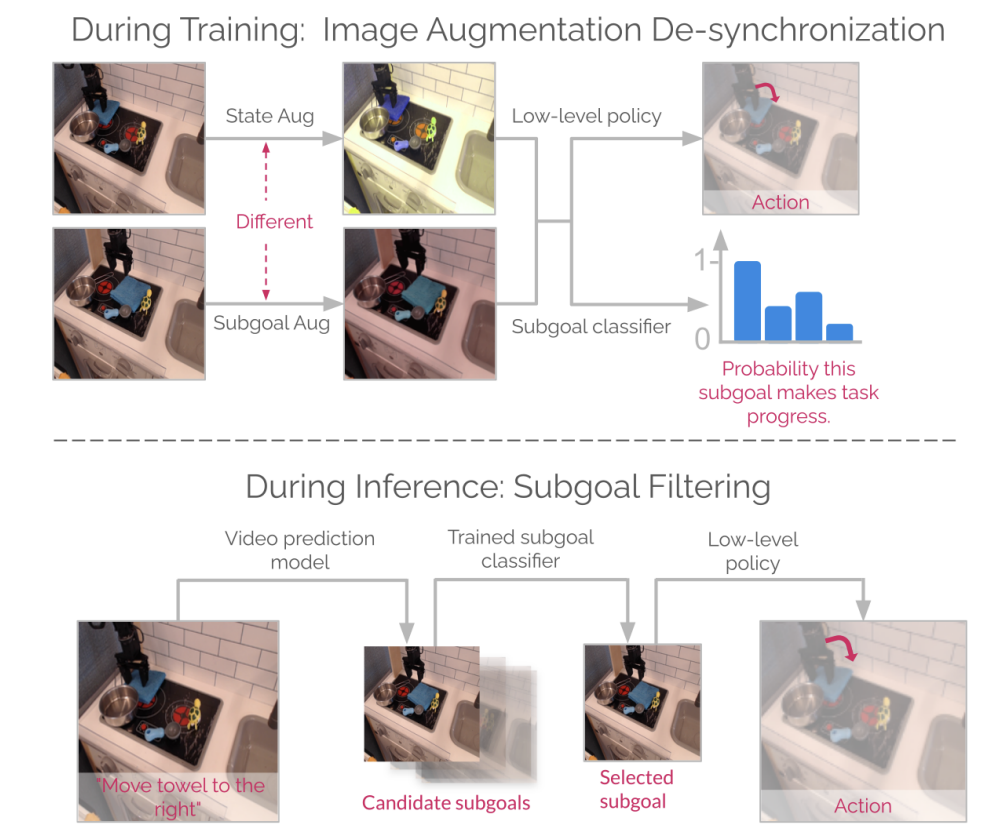
Kyle B Hatch, Ashwin Balakrishna, Oier Mees, Suraj Nair, Seohong Park, Blake Wulfe, Masha Itkina, Benjamin Eysenbach, Sergey Levine, Thomas Kollar, Benjamin Burchfiel International Conference on Robotics and Automation (ICRA), 2025 Website / PDF Learning performant hierarchical imitation learning policies by improving the interface between goal proposal networks and low-level control policies. |
|
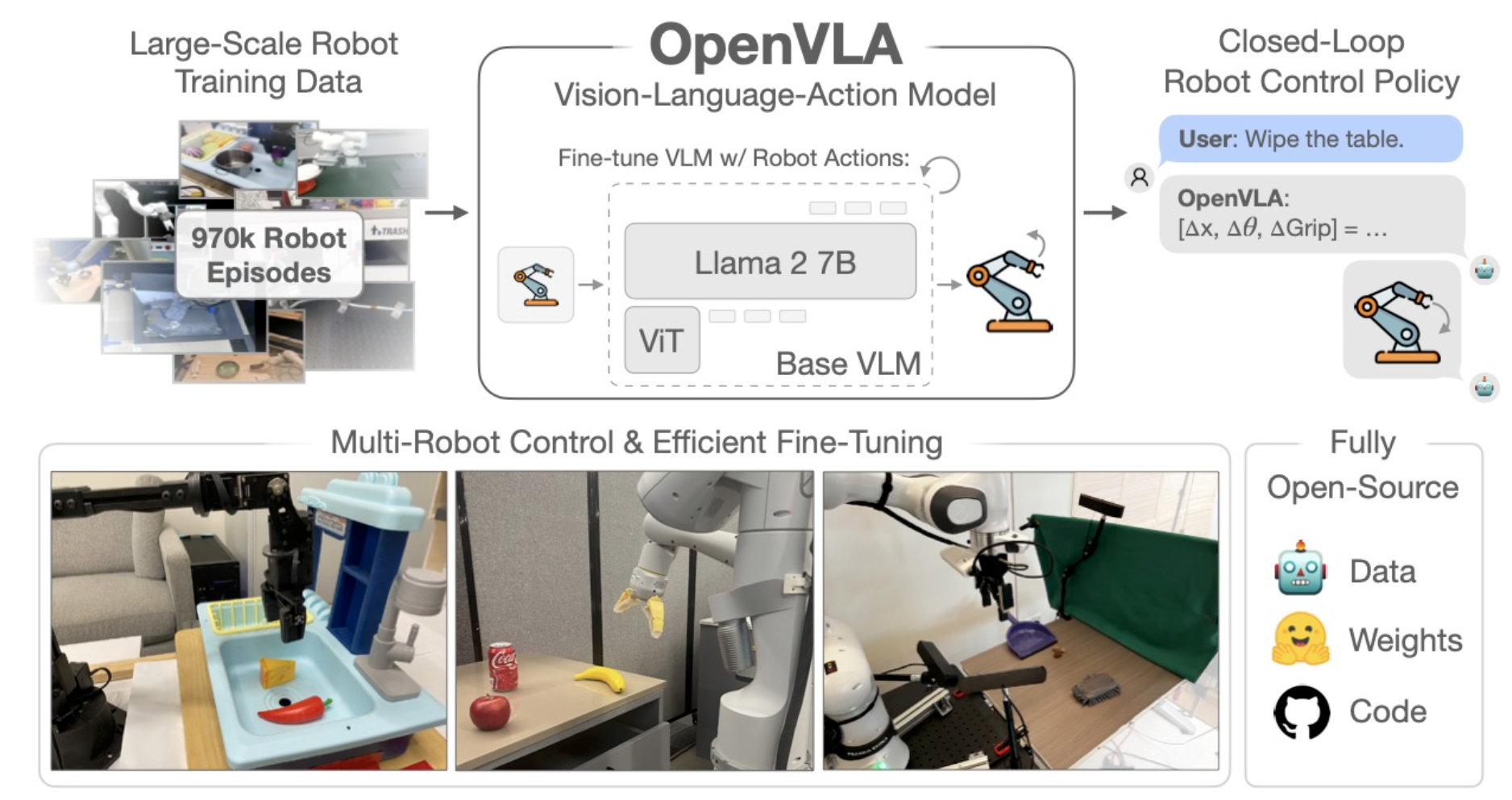
Moo Jin Kim*, Karl Pertsch*, Siddharth Karamcheti*, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn Conference on Robot Learning (CoRL), 2024 - Outstanding Paper Award Finalist Website / PDF Fully open-source vision-language-action model for general-purpose robotic manipulation. Exhibits strong performance both in the zero-shot and finetuning regimes. |
|
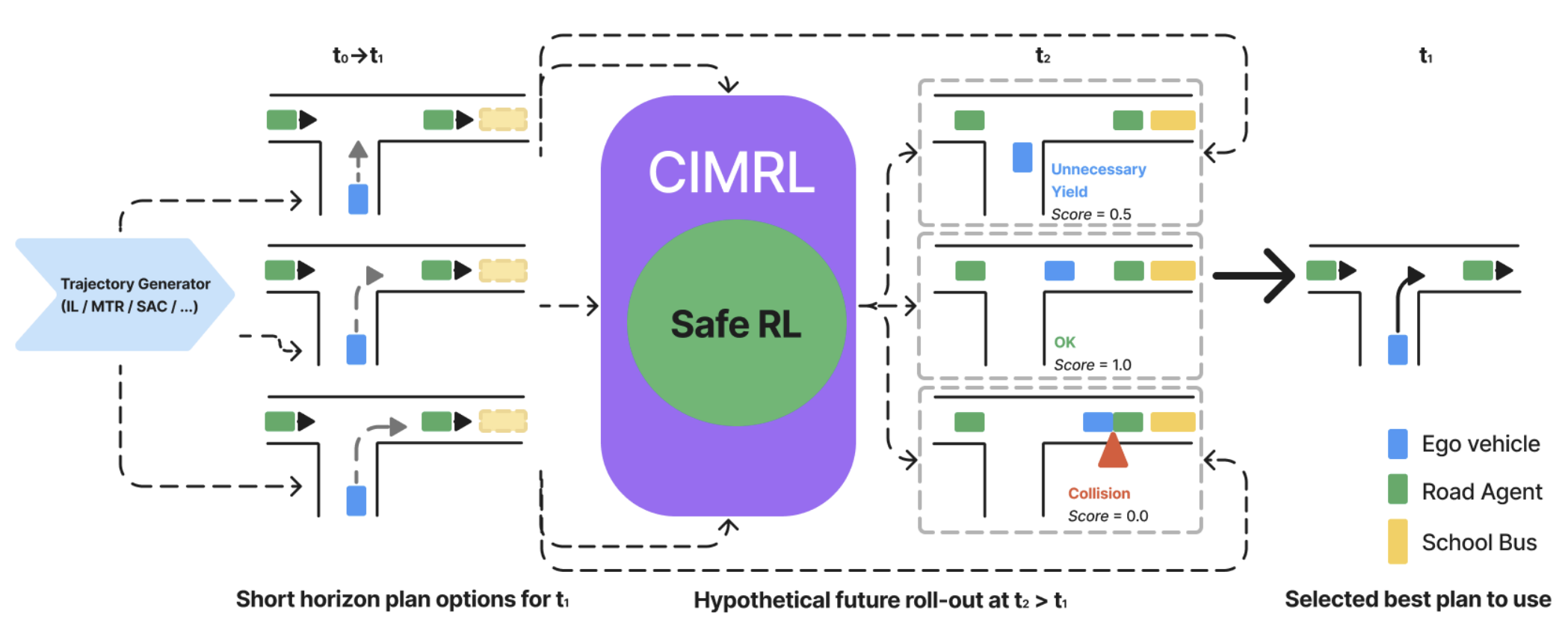
Jonathan Booher, Khashayar Rohanimanesh, Junhong Xu, Vladislav Isenbaev, Ashwin Balakrishna, Ishan Gupta, Wei Liu, Aleksandr Petiushko Preprint, 2025 Website / PDF Develops a safe reinforcement learning system for autonomous motion selection as part of the NuroDriver. Tested extensively in simulation and real world autonomous trials! |

|
Open X-Embodiment Collaboration (>150 authors) International Conference on Robotics and Automation (ICRA), 2024 - Best Conference Paper Website / PDF A large-scale cross-embodiment dataset and results suggesting positive policy transfer across robot embodiments. |

|
Alexander Khazatsky*, Karl Pertsch*, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, et al. (~100 authors) Robotics Science and Systems (RSS), 2024 Website / PDF A large-scale, in-the-wild robot manipulation dataset of 75K+ trajectories collected in various settings such as homes, labs, offices and more across multiple continents! Initial experiments suggest that co-training policies with DROID significantly improves policy robustness and OOD generalization. |
|
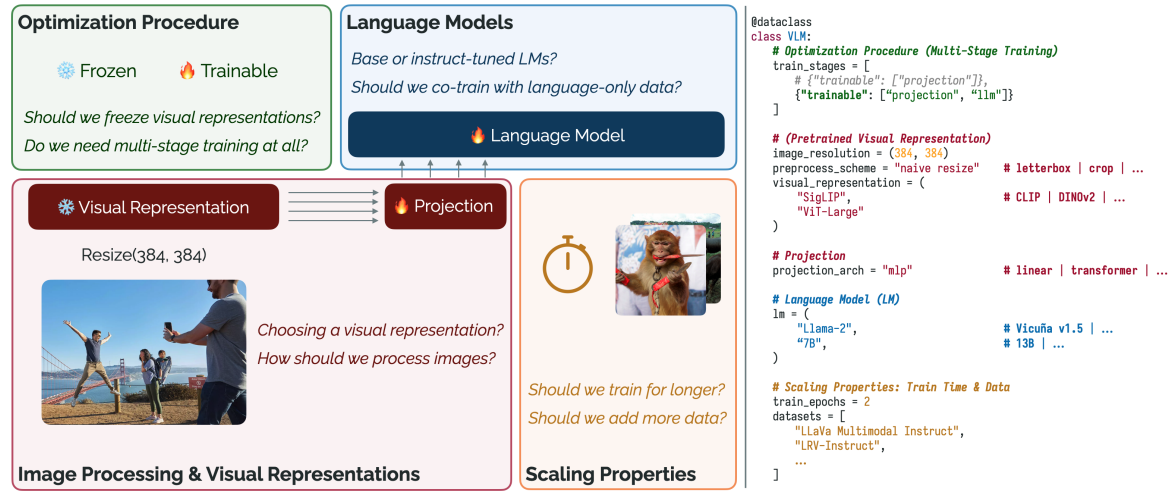
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh International Conference on Machine Learning (ICML), 2024 Website / PDF A thorough investigation of what design choices matter most for building performant visually-conditioned language models. We release optimized and hackable training code, evaluation code, and all trained models for the community to build on. |
|
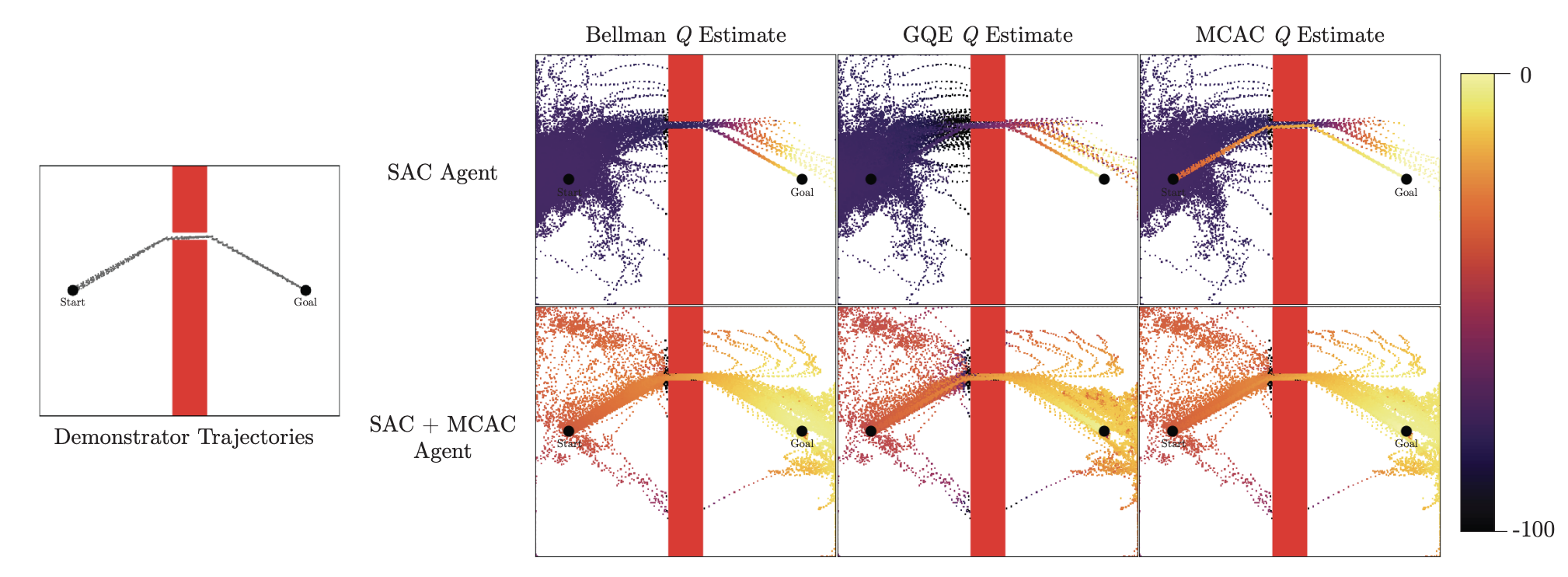
Albert Wilcox, Ashwin Balakrishna, Jules Dedieu, Wyame Benslimane, Daniel Brown, Ken Goldberg Conference on Neural Information Processing Systems (NeurIPS), 2022 Website / PDF A simple reinforcement learning algorithm that can be applied to any existing actor critic method to accelerate exploration for sparse reward tasks. |
|
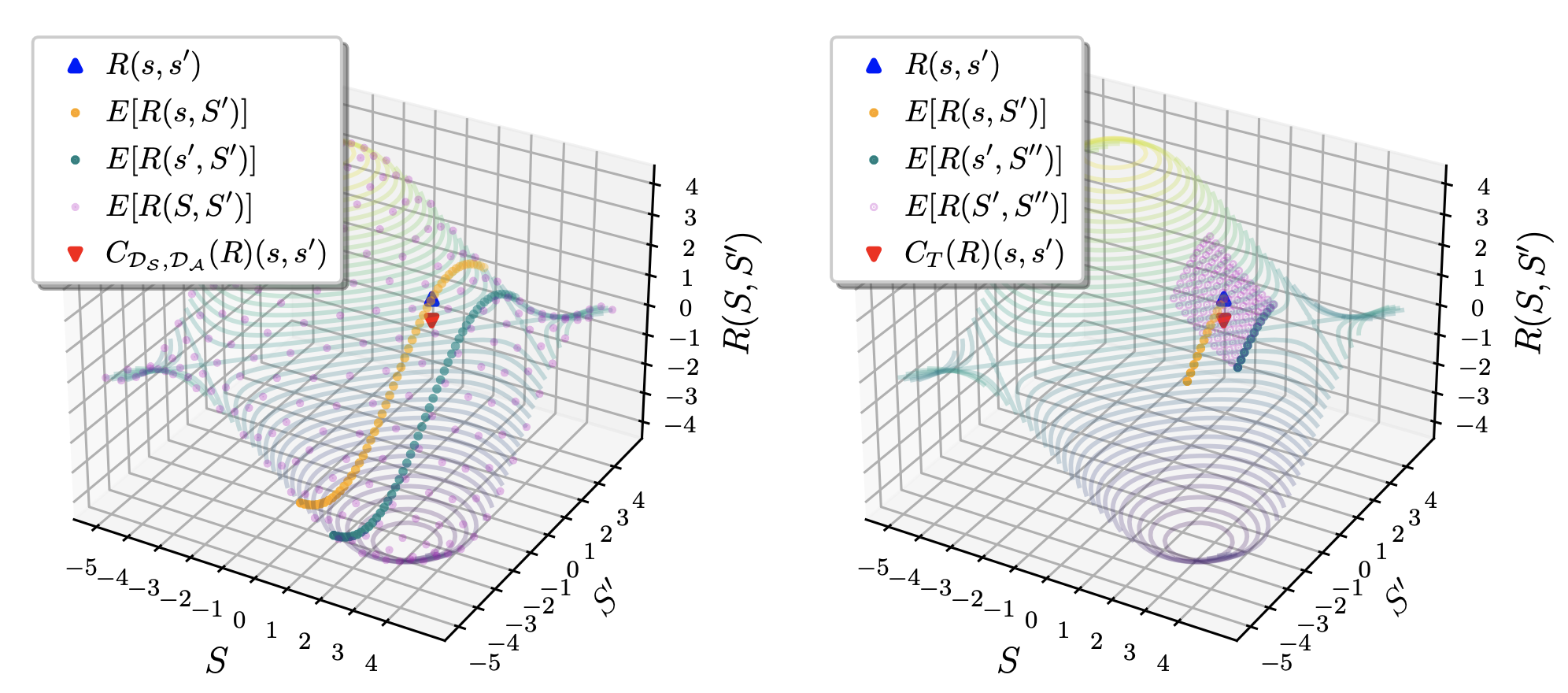
Blake Wulfe, Ashwin Balakrishna, Logan Ellis, Jean Mercat, Rowan McAllister, Adrien Gaidon International Conference on Learning Representations (ICLR), 2022 - Spotlight Presentation Website / PDF An algorithm for robust off policy comparison of learned reward functions. |
|
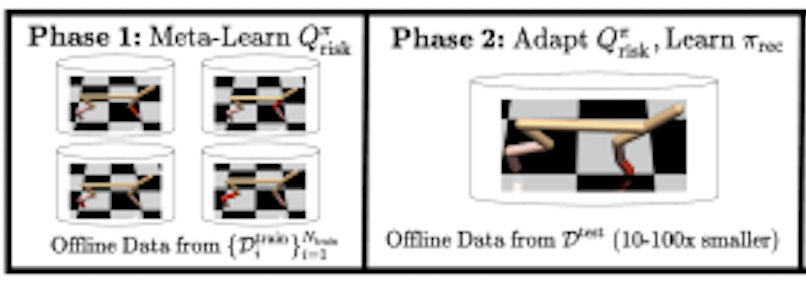
Michael Luo, Ashwin Balakrishna, Brijen Thananjeyan, Suraj Nair, Julian Ibarz, Jie Tan, Chelsea Finn, Ion Stoica, Ken Goldberg NeurIPS Workshop on Safe and Robust Control of Uncertain Systems, 2021 Website / PDF Safe exploration by meta-learning risk measures across environments with different dynamics. |
|
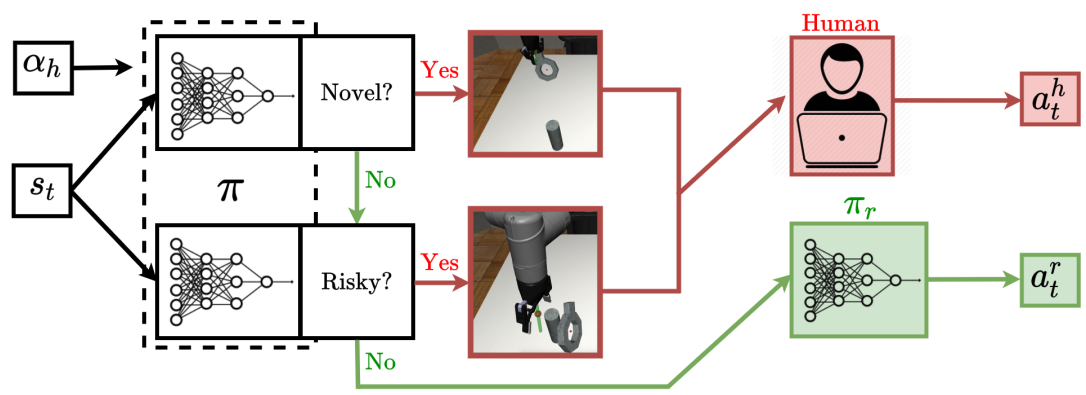
Ryan Hoque, Ashwin Balakrishna, Ellen Novoseller, Albert Wilcox, Daniel S. Brown, Ken Goldberg Conference on Robot Learning (CoRL), 2021 - Oral Presentation Website / PDF An algorithm for query-efficient interactive imitation learning which learns to cede control to a supervisor when (1) in novel states or (2) in bottlenecks where task success is unlikely. |
|
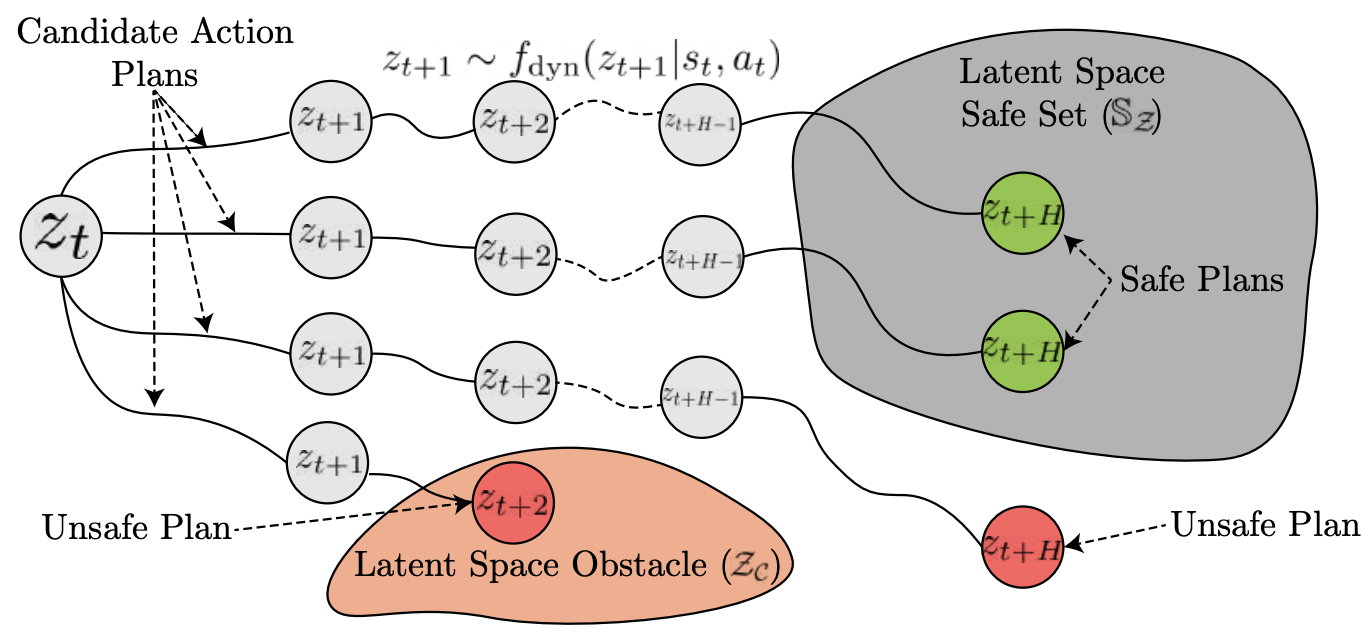
Albert Wilcox*, Ashwin Balakrishna*, Brijen Thananjeyan, Joseph E. Gonzalez, Ken Goldberg Conference on Robot Learning (CoRL), 2021 Website / PDF Safe and efficient RL from image observations by leveraging suboptimal demonstrations to structure exploration and examples of constraint violations to satisfy user-specified constraints. |
|
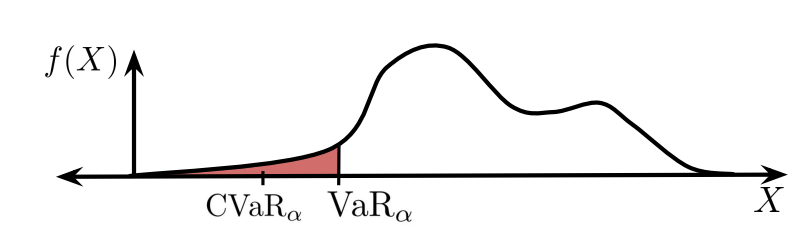
Zaynah Javed*, Daniel Brown*, Satvik Sharma, Jerry Zhu, Ashwin Balakrishna, Marek Petrik, Anca D. Dragan, Ken Goldberg International Conference on Machine Learning (ICML), 2021 Website / PDF A scalable and robust RL algorithm which optimizes for a combination of expected performance and tail risk under a distribution over learned reward functions. |
|
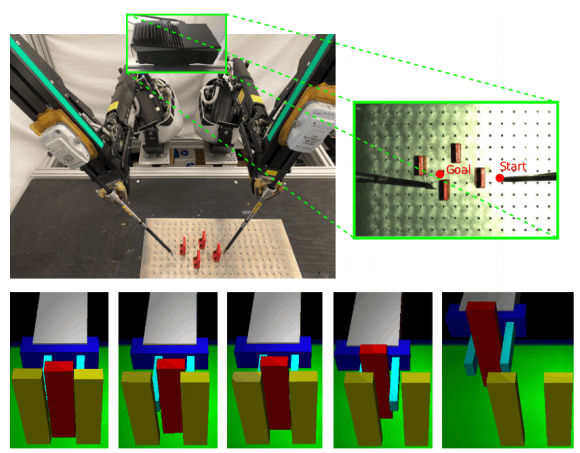
Brijen Thananjeyan*, Ashwin Balakrishna*, Suraj Nair, Michael Luo, Krishnan Srinivasan, Minho Hwang, Joseph E. Gonzalez, Julian Ibarz, Chelsea Finn, Ken Goldberg Robotics and Automation Letters (RA-L) Journal and International Conference on Robotics and Automation (ICRA), 2021 - Mentioned in Google AI Year in Review Website / PDF Mentioned in Google AI Year in Review An algorithm for safe reinforcement learning which utilizes a set of offline data to learn about constraints before policy learning and a pair of policies which seperate the often conflicting objectives of task directed exploration and constraint satisfaction to learn contact rich and visuomotor control tasks. |
|
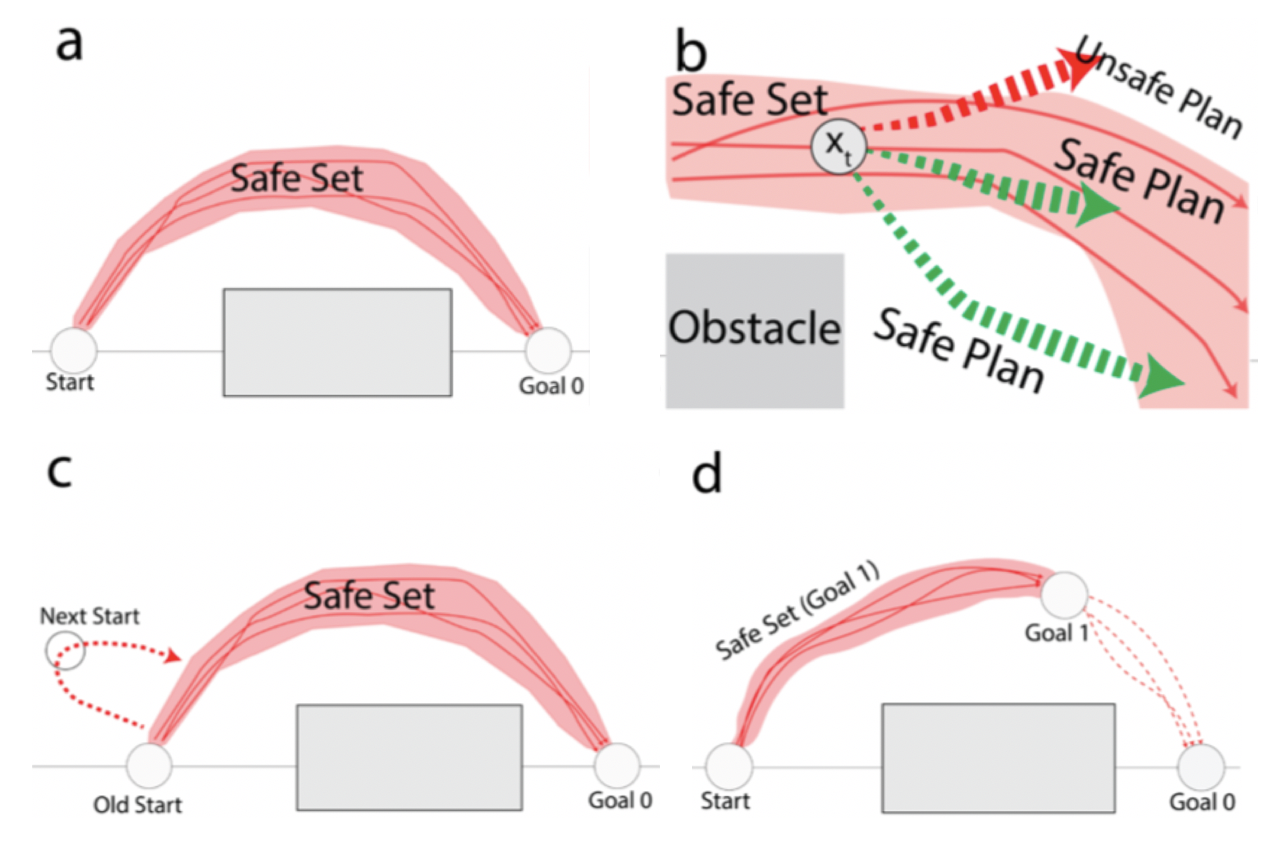
Brijen Thananjeyan*, Ashwin Balakrishna*, Ugo Rosolia, Joseph E. Gonzalez, Aaron Ames, Ken Goldberg Algorithmic Foundations of Robotics (WAFR), 2020 - Invited to IJRR Special Issue Website / PDF An MPC-based algorithm for robotic control (ABC-LMPC) with (1) performance and safety guarantees for stochastic nonlinear systems and (2) the ability to continuously explore the environment and expand the controller domain. |
|
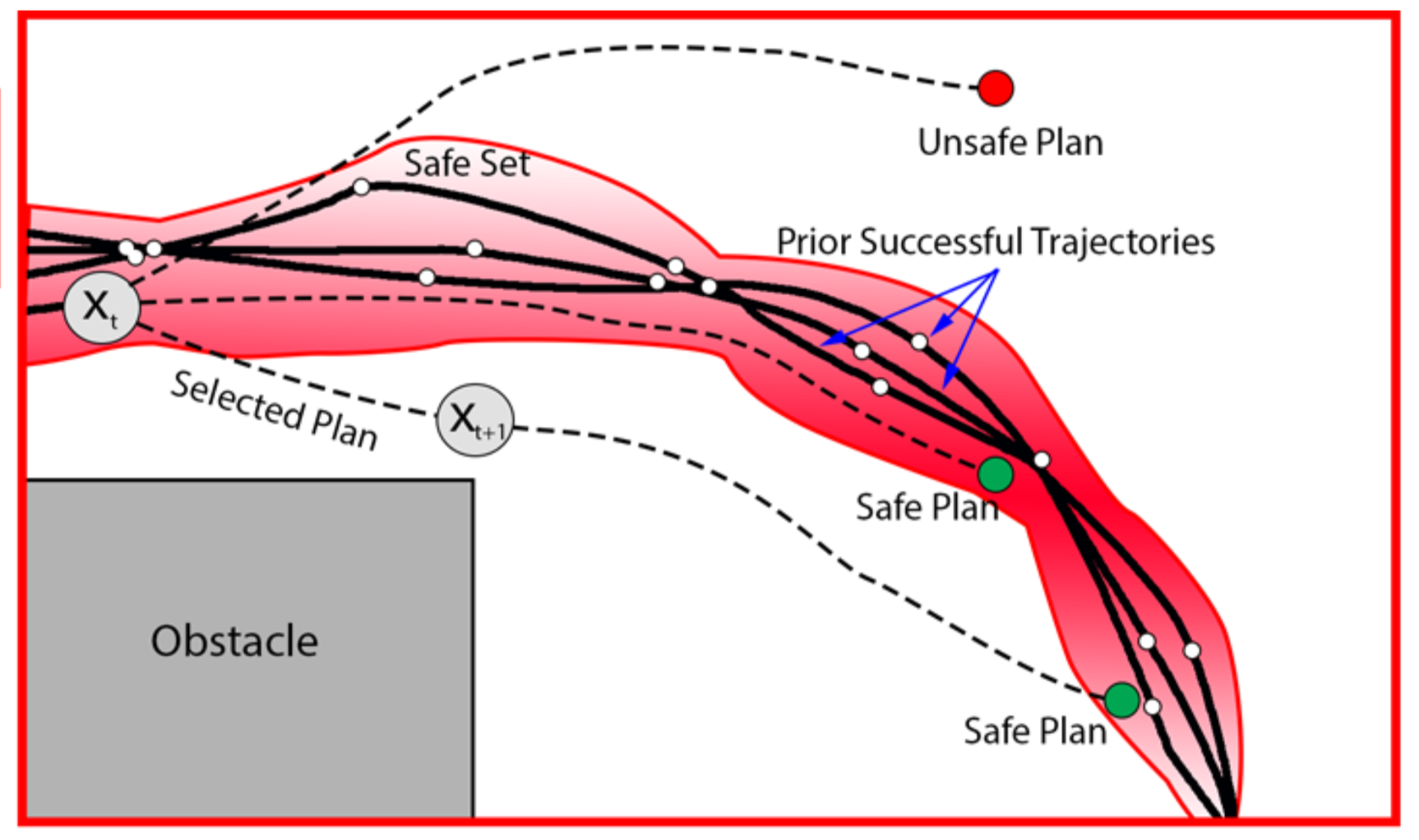
Brijen Thananjeyan*, Ashwin Balakrishna*, Ugo Rosolia, Felix Li, Rowan McAllister, Joseph E. Gonzalez, Sergey Levine, Francesco Borrelli, Ken Goldberg Robotics and Automation Letters (RA-L) Journal and International Conference on Robotics and Automation (ICRA), 2020 Website / PDF A new algorithm for safe and efficient reinforcement learning (SAVED) which leverages a small set of suboptimal demonstrations and prior task successes to structure exploration. SAVED also provides a mechanism for handling state-space constraints by leveraging probabilistic estimates of system dynamics. |
|
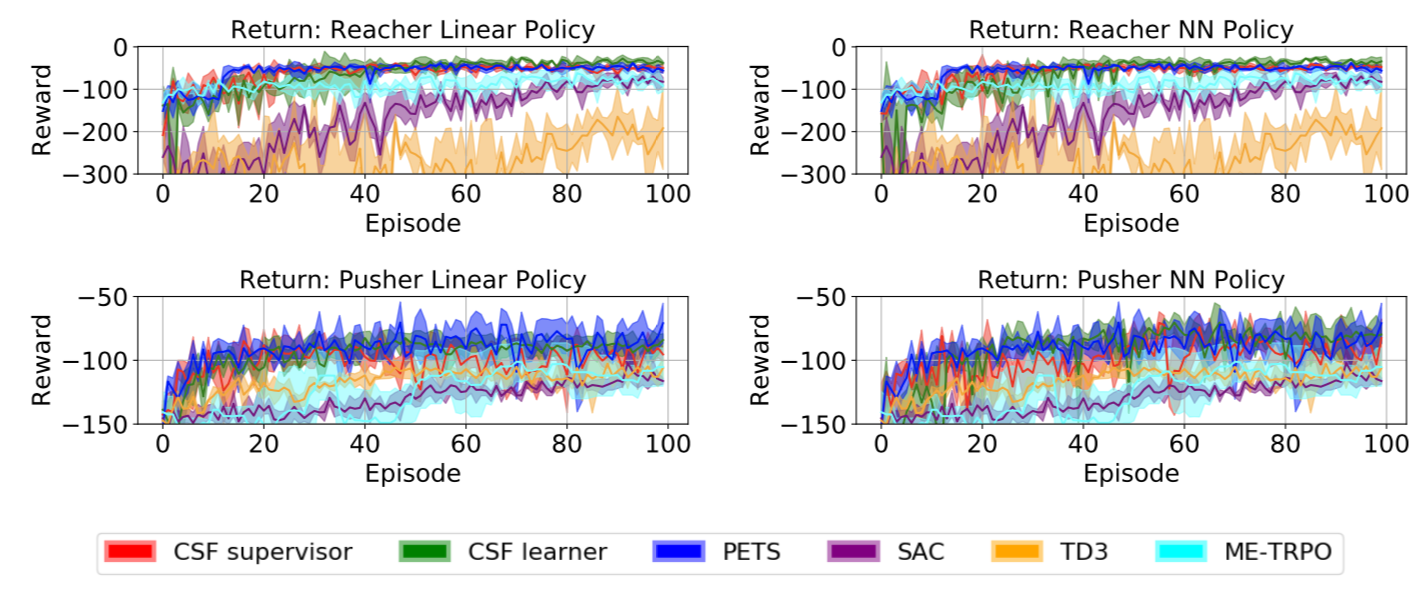
Ashwin Balakrishna*, Brijen Thananjeyan*, Jonathan Lee, Felix Li, Arsh Zahed, Joseph E. Gonzalez, Ken Goldberg Conference on Robot Learning (CoRL), 2019 - Oral Presentation A new formulation of imitiation learning from a non-stationary supervisor, associated theoretical analysis, and a practical algorithm to apply this formulation to develeop an RL algorithm which combines the sample efficiency of model-based RL and the fast policy evaluation enabled by model-free policies. |